Designing a URL shortener looks simple on the surface—but at scale, it becomes a classic distributed systems problem involving performance, scalability, caching, databases, and trade-offs.
In this post, we will design a production-grade URL shortener using a clear 14-step system design framework that you can reuse for any system design interview or real-world architecture discussion.
The 14-Step Design Framework
- Clarify the Problem
- Define Requirements
- Design High-Level Architecture
- Design APIs
- Choose URL Generation Strategy
- Design Data Model
- Optimize Redirect (Read) Flow
- Implement Caching Strategy
- Plan for Scalability
- Handle Failures & Edge Cases
- Security & Abuse Prevention
- Add AI Enhancements (Optional)
- Review Trade-offs
- Summarize Final Architecture
Let’s walk through each step in detail.
Step 1: Clarify the Problem
A URL shortener converts a long URL into a short, unique identifier and redirects users back to the original URL when accessed.
Example:
Long URL → https://www.example.com/articles/system-design/url-shortener
Short URL → https://short.ly/aZ91Kq
At scale, two facts become clear:
- URL creation is infrequent
- URL redirection happens extremely often
This tells us the system is read-heavy, and performance during redirection is the most critical requirement.
Step 2: Define Requirements
Functional Requirements
- Generate a short URL for a given long URL
- Redirect short URLs to original URLs
- Ensure uniqueness of short URLs
- Support optional expiration or custom aliases
Non-Functional Requirements
- Low latency (especially for redirects)
- High availability
- Horizontal scalability
- Data durability
- Fault tolerance
These requirements guide every architectural decision that follows.
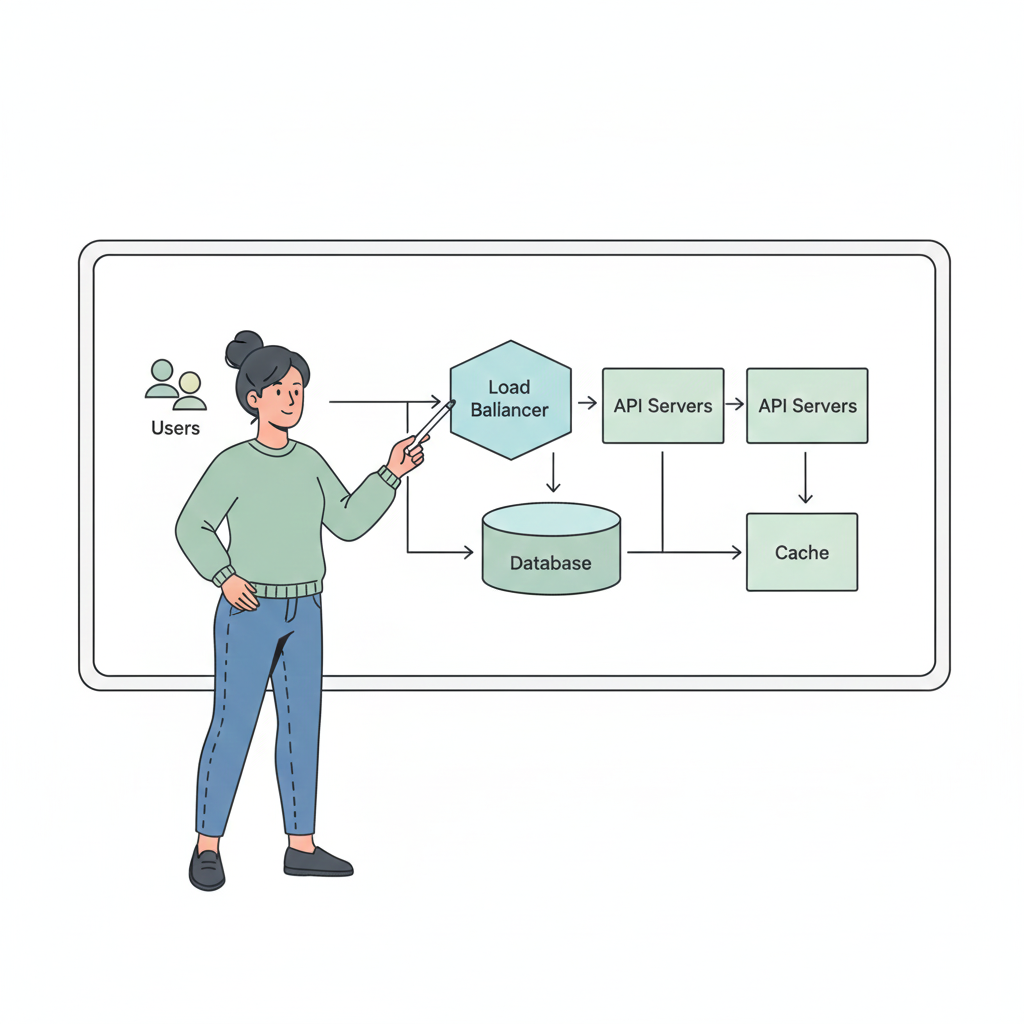
Step 3: Design High-Level Architecture
At a high level, the system consists of:
- Stateless backend services
- A fast in-memory cache
- A durable database
Client
→ API Gateway
→ URL Shortener Service
→ Cache (Redis)
→ Database
The service layer remains stateless, enabling easy horizontal scaling behind a load balancer.
Step 4: Design APIs
We need only two core APIs.
Create Short URL
POST /shorten
{
"longUrl": "https://example.com/..."
}
Response:
{
"shortUrl": "https://short.ly/aZ91Kq"
}
Redirect API
GET /aZ91Kq → HTTP 301 Redirect
Using 301 redirects helps with SEO and caching at browser and CDN levels.
Step 5: Choose URL Generation Strategy
This is a core design decision.
Recommended Approach: Auto-Increment ID + Base62 Encoding
- Generate a unique numeric ID
- Encode it using Base62 (
a–z,A–Z,0–9) - Use the encoded value as the short code
Example:
ID = 125 → Base62 = aZ
Why this works well
- Guaranteed uniqueness
- Short URLs
- Simple logic
- No collision handling needed
Predictability can be reduced by starting IDs at a random offset or adding light obfuscation.
Step 6: Design Data Model
We need durable storage to map short URLs to long URLs.
Example Table: urls
| Field | Description |
|---|---|
| id | Auto-increment primary key |
| short_code | Base62 encoded string |
| long_url | Original URL |
| created_at | Timestamp |
| expires_at | Optional expiration |
| is_active | Soft delete flag |
A relational database (MySQL/PostgreSQL) works well initially and is easy to evolve.
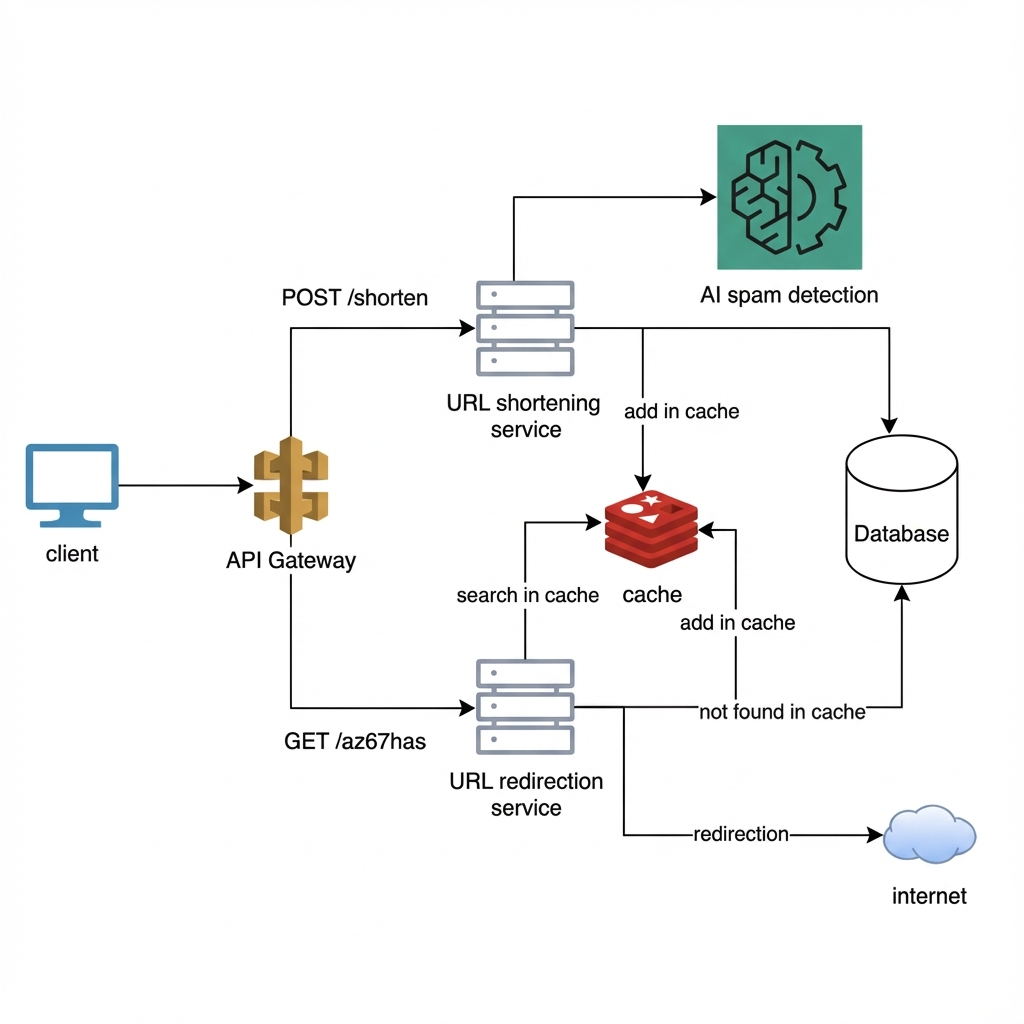
Step 7: Optimize Redirect (Read) Flow
Redirect performance defines user experience.
Redirect Flow
- User hits short URL
- Service checks cache
- If found → redirect immediately
- If not found:
- Fetch from database
- Store in cache
- Redirect user
This ensures most requests never hit the database, keeping latency extremely low.
Step 8: Implement Caching Strategy
Caching is critical for scalability.
- Cache key:
short_code - Cache value:
long_url - TTL: Long (URLs rarely change)
Using Redis or Memcached allows the system to handle millions of redirects per second with minimal database load.
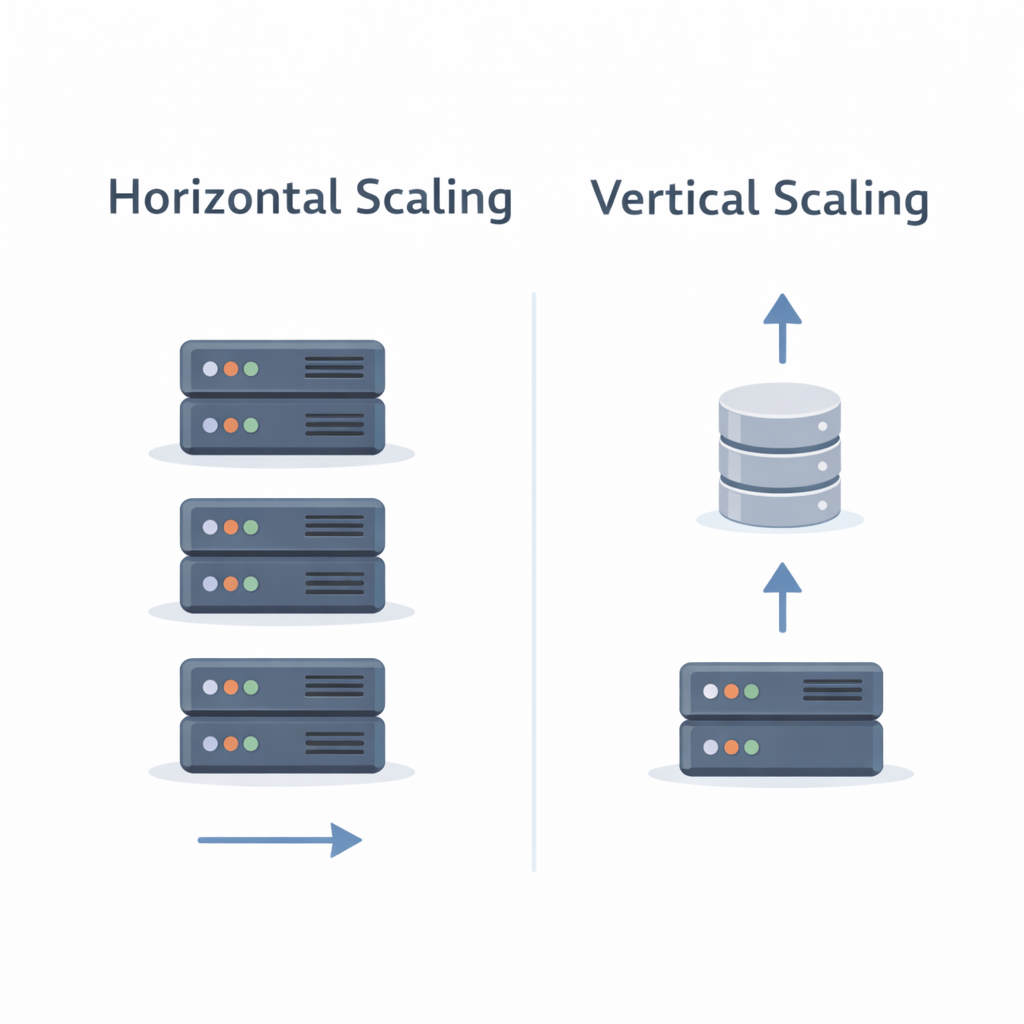
Step 9: Plan for Scalability
Read Scalability
- Cache-first architecture
- CDN in front of redirect endpoints
- Horizontal scaling of services
Write Scalability
- Centralized ID generation
- Batched or async writes if needed
Database Scaling
- Read replicas
- Sharding by ID ranges when data grows
Step 10: Handle Failures & Edge Cases
A real system must assume failures.
- Cache outage → fallback to database
- Database retry on transient failures
- Graceful handling of expired URLs
- Clear error responses for invalid short codes
This prevents small failures from becoming outages.
Step 11: Security & Abuse Prevention
URL shorteners are often abused.
Basic protections include:
- URL validation
- IP-based rate limiting
- Blocking known malicious domains
- HTTPS everywhere
- Request throttling per user
Step 12: Add AI Enhancements (Optional)
AI should enhance, not complicate, the system.
Practical AI Use Cases
- Malicious URL detection (phishing, scams)
- Bot vs human traffic detection
- Smart expiration of unused URLs
- Analytics insights from click behavior
AI is not required for core URL generation or redirection.
Step 13: Review Trade-offs
Every decision has trade-offs.
| Decision | Trade-off |
|---|---|
| Base62 IDs | Predictable but simple |
| Cache-first reads | Eventual consistency |
| SQL database | Easier early scaling |
| AI features | Extra cost and complexity |
Good system design is about making conscious trade-offs, not avoiding them.
Step 14: Summarize Final Architecture
The final system is:
- Simple
- Read-optimized
- Horizontally scalable
- Interview-ready
- Production-practical
Client
→ API Gateway
→ Stateless URL Service
→ Cache (fast reads)
→ Database (durable storage)
What’s Next?
With this foundational case study complete, we’re ready to design more complex systems involving fan-out, retries, and real-time delivery.