Rate limiting is a critical building block in modern distributed systems. Almost every large-scale system, whether it is an API platform, social network, payment gateway, or SaaS product, relies on rate limiting to protect itself from abuse, ensure fair usage, and control infrastructure costs.
In this blog, we will design a scalable, distributed rate limiter, focusing on real-world constraints, trade-offs, and production-ready architecture.
Index
- What Is Rate Limiting and Why It Is Needed
- Functional and Non-Functional Requirements
- Traffic Estimation and Scale Assumptions
- High-Level Architecture
- Rate Limiting Strategies (What to Limit)
- Core Rate Limiting Algorithms
- Distributed Rate Limiter Design
- Data Store Design (Redis-based)
- API Design and Error Handling
- Rate Limit Lifecycle (Request Journey)
- Scalability Considerations
- Fault Tolerance and Failure Scenarios
- Trade-offs and Design Decisions
- Summary
1. What Is Rate Limiting and Why It Is Needed
Rate limiting controls how many requests a client can make within a given time window.
Without rate limiting:
- A single user can overload your system
- Bots can scrape or abuse APIs
- Traffic spikes can cause cascading failures
- Infrastructure costs can grow uncontrollably
Rate limiting acts as a protective shield, especially at system boundaries like:
- Public APIs
- Login endpoints
- Payment flows
- Search endpoints
2. Functional and Non-Functional Requirements
Functional Requirements
- Limit requests per user, IP, or API key
- Support different limits for different endpoints
- Return clear error responses when limits are exceeded
- Work in a distributed environment
Non-Functional Requirements
- Low latency (sub-millisecond decisions)
- Highly available
- Horizontally scalable
- Eventually consistent (strong consistency is not mandatory)
- Minimal impact on request throughput
3. Traffic Estimation and Scale Assumptions
Let’s assume:
- 50 million daily active users
- Peak traffic: 500K requests/sec
- Each user allowed: 100 requests/minute
- Thousands of API servers behind load balancers
This immediately rules out:
- Single-node in-memory counters
- Synchronous database writes per request
We need a centralized but fast, distributed-friendly solution.
4. High-Level Architecture
At a high level, the rate limiter sits before application services.
Flow:
Client → Load Balancer → Rate Limiter → API Service
Key Components:
- API Gateway / Edge Layer
- Rate Limiting Service
- Distributed Cache (Redis)
- Monitoring & Metrics System
Rate limiting can be implemented:
- At API Gateway (preferred)
- As a sidecar
- As a shared service
5. Rate Limiting Strategies (What to Limit)
Common strategies include:
- IP-based: Simple, but fails behind NATs
- User-based: Requires authentication
- API key-based: Ideal for public APIs
- Endpoint-based: Different limits per API
- Combination: (User + Endpoint)
In production systems, composite keys are commonly used:
(user_id + endpoint)
6. Core Rate Limiting Algorithms
Different rate limiting algorithms solve different problems. Choosing the right one depends on traffic patterns, burst tolerance, and accuracy vs performance trade-offs.
Let’s look at the most commonly used algorithms with practical examples.
1. Fixed Window Counter
How it works:
- Requests are counted within a fixed time window (e.g., 1 minute).
- Once the limit is reached, all further requests are blocked until the window resets.
Example:
- Limit: 100 requests per minute
- Window: 12:00–12:01
- A user sends 100 requests at 12:00:55
- At 12:01:00, the counter resets and the user can send 100 more requests immediately
Problem:
This causes a burst at window boundaries, potentially allowing 200 requests in a few seconds.
Where it’s used:
- Simple internal tools
- Low-traffic admin APIs
Why it’s usually avoided:
- Poor traffic smoothing
- Unfair burst behavior
2. Sliding Window Log
How it works:
- Stores the timestamp of every request
- On each request, counts how many timestamps fall within the last time window
Example:
- Limit: 100 requests per 60 seconds
- System checks how many requests occurred in the last rolling 60 seconds
- If count ≥ 100 → reject request
Advantages:
- Very accurate
- No burst problem
Problems:
- High memory usage
- Expensive cleanup of old timestamps
Where it’s used:
- Low-volume systems
- Security-sensitive endpoints (login, OTP)
3. Sliding Window Counter (Hybrid)
How it works:
- Divides time into small windows
- Uses weighted counts from the current and previous window
Example:
- Window size: 1 minute
- Current window: 30 requests
- Previous window: 70 requests
- Weighted total ≈ 100
Why it’s popular:
- Much more accurate than fixed window
- Much cheaper than sliding log
Where it’s used:
- API gateways
- Distributed systems with moderate accuracy needs
4. Token Bucket (Most Common in Production)
How it works:
- Tokens are added to a bucket at a fixed rate
- Each request consumes one token
- If no tokens are available, the request is rejected
Example:
- Bucket size: 100 tokens
- Refill rate: 1 token per second
- A user sends:
- 50 requests instantly → allowed (burst supported)
- Next 60 requests → only 50 allowed, rest rejected
- Tokens refill gradually over time
Why it’s preferred:
- Allows controlled bursts
- Smooths traffic naturally
- Simple to implement in Redis
Real-world usage:
- API rate limiting (AWS API Gateway)
- User-facing APIs
- Payment & search endpoints
5. Leaky Bucket
How it works:
- Requests enter a queue
- Requests leave the queue at a constant rate
Example:
- Processing rate: 10 requests/sec
- Incoming rate: 50 requests/sec
- Extra requests overflow and are dropped
Key difference from Token Bucket:
- Token Bucket allows bursts
- Leaky Bucket enforces strict smoothing
Where it’s used:
- Traffic shaping
- Network routers
- Systems where burstiness is harmful
Which Algorithm Should You Choose?
| Use Case | Recommended Algorithm |
|---|---|
| Public APIs | Token Bucket |
| Login / OTP | Sliding Window Log |
| Simple systems | Fixed Window |
| Traffic smoothing | Leaky Bucket |
| API Gateways | Sliding Window Counter |
In most large-scale distributed systems, Token Bucket + Redis is the default choice because it balances accuracy, performance, and simplicity.
Key takeaway:
Rate limiting is not about absolute precision. It’s about protecting the system while keeping latency low and behavior predictable.
7. Distributed Rate Limiter Design
In a distributed system:
- Requests hit different servers
- State must be shared
Solution: Use a centralized, in-memory datastore like Redis.
Each request:
- Computes a rate-limit key
- Atomically checks and updates counters in Redis
- Allows or rejects the request
Atomicity is achieved using:
- Redis Lua scripts
- Redis INCR + TTL patterns
8. Data Store Design (Redis-Based)
Why Redis?
- In-memory (low latency)
- Atomic operations
- TTL support
- Horizontally scalable via clustering
Key Design Example:
rate_limit::{endpoint}
Value:
- Remaining tokens
- Last refill timestamp
TTL:
- Automatically expires unused keys
- Prevents memory leaks
Redis Cluster ensures:
- Horizontal scaling
- Partitioning by key hash
- High availability with replicas
9. API Design and Error Handling
Example API Response (Success):
HTTP/1.1 200 OK
X-Rate-Limit-Limit: 100
X-Rate-Limit-Remaining: 42
X-Rate-Limit-Reset: 1699999999
Example API Response (Rate Limited):
HTTP/1.1 429 Too Many Requests
{
"error": "RATE_LIMIT_EXCEEDED",
"message": "Too many requests. Try again later."
}
Standard HTTP status code 429 is critical for client-side handling.
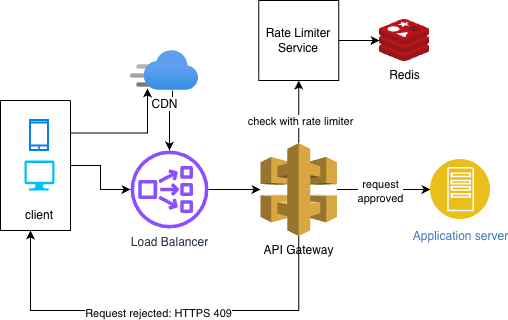
10. Rate Limit Lifecycle (Request Journey)
Let’s follow a single API request:
- Client sends request
- Load balancer routes to API Gateway
- Rate limiter generates key
- Redis Lua script checks token availability
- Token deducted if available
- Request forwarded to backend service
- If limit exceeded → immediate 429 response
This entire flow must complete in microseconds.
11. Scalability Considerations
Horizontal Scaling
- API servers are stateless
- Redis cluster scales independently
Hot Key Problem
- Popular users or endpoints can overload a single shard
- Solutions:
- Key sharding
- Local in-memory caching (with fallback)
- Separate limits for heavy endpoints
Edge Rate Limiting
- Apply coarse limits at CDN / API Gateway
- Fine-grained limits deeper in the system
12. Fault Tolerance and Failure Scenarios
Redis Down
Options:
- Fail-open (allow traffic)
- Fail-closed (block traffic)
- Hybrid (allow limited traffic)
Most systems choose fail-open to avoid outages.
Partial Network Failure
- Use timeouts
- Graceful degradation
- Circuit breakers
13. Trade-offs and Design Decisions
| Decision | Trade-off |
|---|---|
| Redis vs DB | Speed vs durability |
| Token Bucket | Slight approximation |
| Centralized store | Simplicity vs dependency |
| Fail-open | Safety vs abuse |
No rate limiter is perfect. The goal is controlled imperfection.
14. Summary
A well-designed rate limiter:
- Protects system stability
- Improves fairness
- Reduces cost
- Scales with traffic
In real-world systems, rate limiting is not an afterthought. It is a first-class architectural concern and often the difference between graceful degradation and total outage.