Understanding Large Language Models as Production Systems, Not Just Models
Large Language Models (LLMs) are often introduced as “AI models that generate text.”
But in real-world production environments, LLMs are not standalone models — they are complex distributed systems.
What users interact with is not GPT, Claude, or any model directly.
They interact with LLM systems — architectures that combine models, APIs, data pipelines, retrieval layers, memory systems, orchestration engines, monitoring infrastructure, and scalability mechanisms.
This blog introduces LLMs from a system design perspective:
not as AI research artifacts, but as production-grade software systems.
LLM Systems vs LLM Models
A model is just one component.
An LLM system includes:
- Model serving infrastructure
- Inference APIs
- Data pipelines
- Retrieval systems
- Memory layers
- Orchestration logic
- Observability tools
- Security layers
- Cost control mechanisms
- Scaling architecture
- Latency optimization
- Reliability engineering
In simple terms:
Model = intelligence engine
System = intelligence delivery platform
This is the same evolution we saw with databases:
- Database ≠ Data system
- Web server ≠ Web platform
- Model ≠ AI system
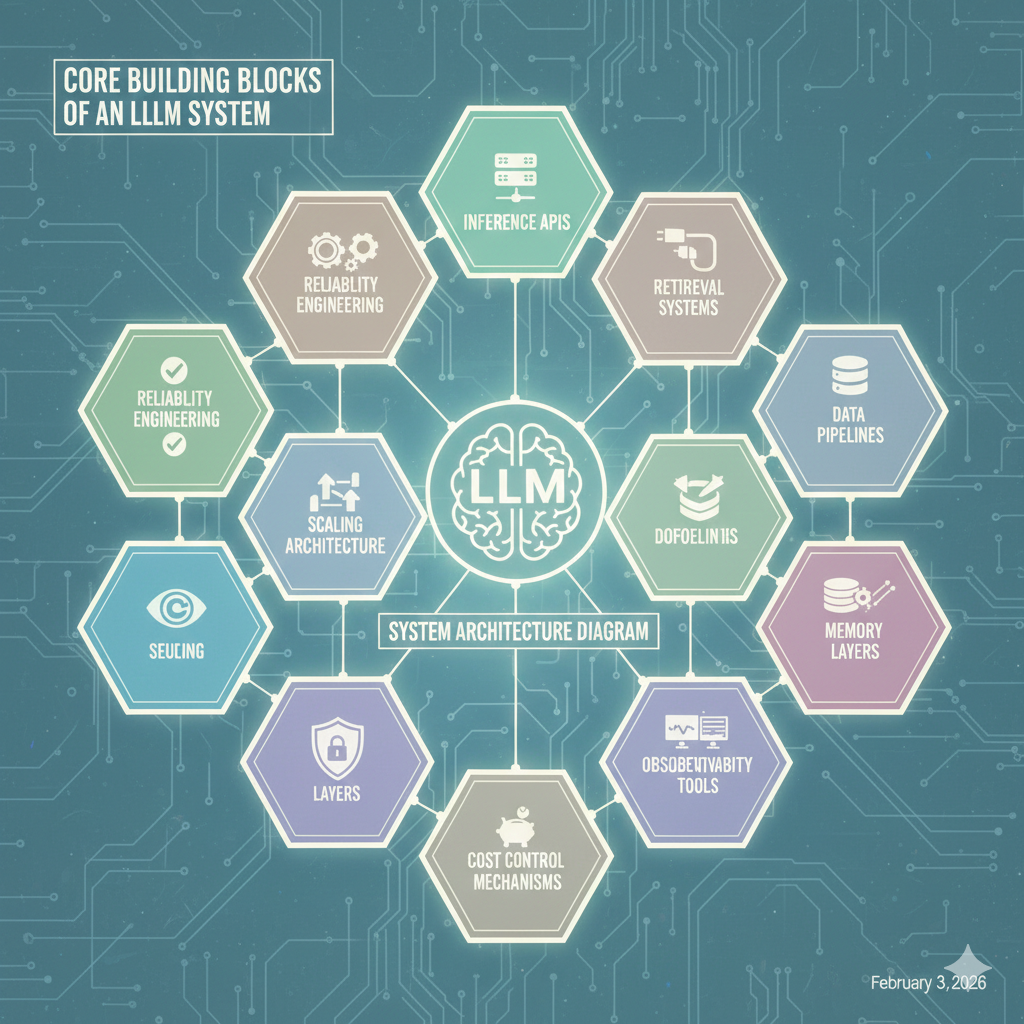
Core Building Blocks of an LLM System
A modern LLM system is composed of multiple architectural layers:
1. Model Layer (Intelligence Core)
This includes:
- Foundation models (GPT-4, Claude, Gemini, LLaMA, Mistral, DeepSeek, etc.)
- Fine-tuned models
- Domain-specific models
- Open-weight vs closed-weight models
- Multi-model strategies (routing between models)
Modern systems often use model orchestration, not a single model:
- cheap model for simple tasks
- powerful model for complex reasoning
- domain model for specialized queries
This is called model routing architecture.
2. Inference Layer (Serving Infrastructure)
Models don’t run directly in apps — they are deployed via inference systems:
- API-based serving (OpenAI API, Anthropic API, Azure OpenAI, Bedrock)
- Self-hosted inference (vLLM, TGI, TensorRT-LLM, Ray Serve)
- GPU clusters
- Model gateways
- Load balancing
- Autoscaling inference pods
This layer handles:
- request batching
- token streaming
- latency optimization
- GPU scheduling
- throughput control
- cost optimization
This is where AI meets cloud infrastructure.
3. API Layer (Integration Interface)
This is how applications interact with LLM systems:
- REST APIs
- streaming APIs
- WebSockets
- SDKs
- internal service APIs
This layer manages:
- authentication
- rate limiting
- request validation
- retries
- fallback logic
- model selection
- observability hooks
From a system view:
LLM APIs behave like distributed microservices.
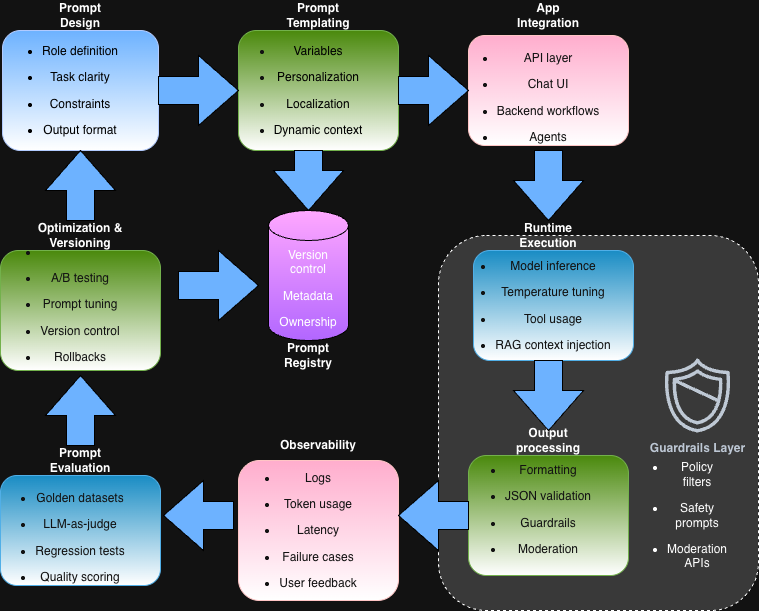
4. Context & Control Layer (Prompt + Policy Layer)
This layer defines how intelligence is controlled:
- system prompts
- role instructions
- policies
- constraints
- safety rules
- output formatting
- reasoning boundaries
This is not just “prompt engineering” — it’s AI control engineering.
Modern systems use:
- structured prompts
- templates
- policy engines
- guardrails
- validation layers
- schema-based outputs
5. Knowledge Layer (Data Integration)
Pure LLMs are limited by training data.
So production systems add:
- Retrieval systems
- Knowledge bases
- Vector databases
- Search engines
- Document stores
- APIs
- Internal tools
This creates grounded AI systems, where models reason over real data.
This is where RAG (Retrieval-Augmented Generation) comes in:
AI + Data = Production intelligence
6. Memory Layer
Memory is what turns chatbots into systems:
- session memory
- conversation memory
- long-term memory
- user memory
- organizational memory
Implemented via:
- databases
- vector stores
- caches
- state machines
- memory services
Memory transforms:
Stateless AI → Stateful AI systems
7. Orchestration Layer
This controls flows like:
- multi-step reasoning
- tool calling
- API chaining
- workflows
- planning
- execution
- fallback handling
This layer uses:
- workflow engines
- agent frameworks
- orchestration pipelines
- state machines
- task queues
This is how agents are built.
8. Observability & Reliability Layer
Production AI systems must be observable:
- tracing
- logging
- metrics
- latency tracking
- error analysis
- hallucination detection
- cost tracking
- token monitoring
AI observability is becoming its own field:
LLMOps / AI Ops
LLM Systems as Distributed Systems
Modern LLM platforms behave like distributed systems:
- multiple services
- async pipelines
- queues
- caches
- microservices
- data stores
- load balancers
- global routing
- multi-region deployment
They face the same problems:
- latency
- scaling
- reliability
- failure handling
- cost management
- traffic spikes
- concurrency control
- consistency
This means:
LLM engineering = Distributed systems engineering + AI
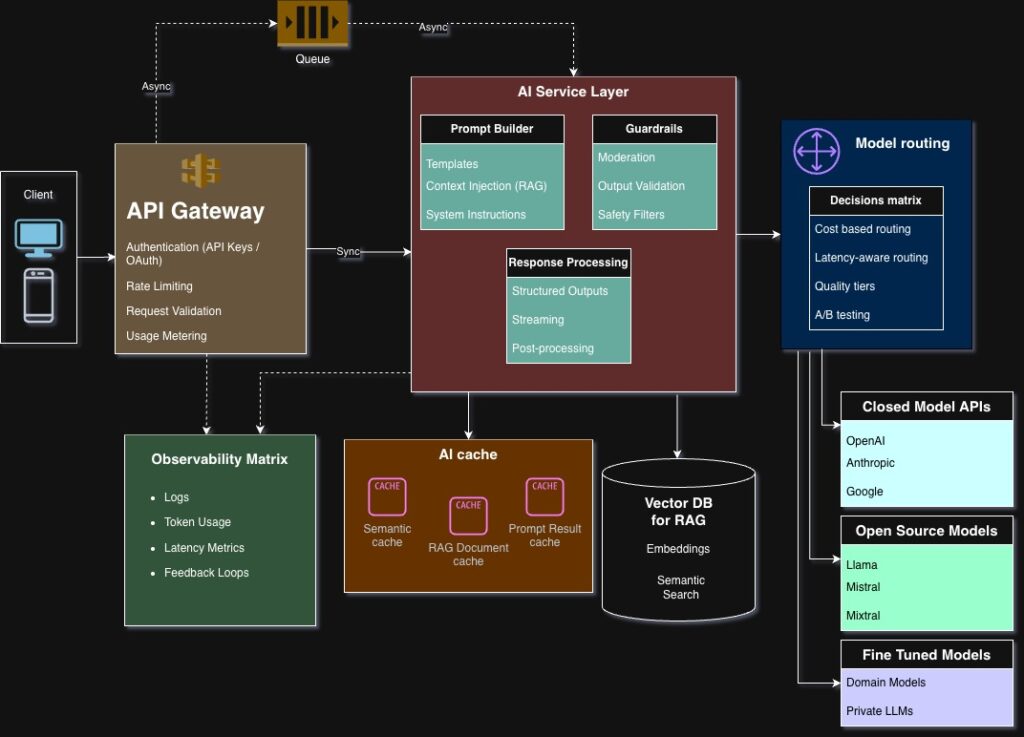
Architecture View (Conceptual)
A simplified LLM system flow:
User
→ API Gateway
→ Auth + Rate Limiting
→ Orchestration Layer
→ Context Builder
→ Retrieval System (optional)
→ Vector DB / Search
→ Model Router
→ Inference Engine
→ Response Validator
→ Memory Store
→ Observability System
→ Response to User
This is a pipeline, not a model call.
Why LLM Systems Matter
Because production AI failures are system failures, not model failures:
- latency issues
- high cost
- hallucinations
- data leaks
- scaling breakdown
- API outages
- GPU bottlenecks
- memory corruption
- pipeline failures
Real-world AI problems are architectural problems.
Industry Direction (2025+)
Modern LLM systems are evolving toward:
- multi-model architectures
- agent ecosystems
- AI microservices
- AI platforms (not apps)
- AI operating layers
- AI infrastructure stacks
- AI marketplaces
- AI operating models
Companies are building:
- internal AI platforms
- AI developer platforms
- AI service layers
- AI operating systems
Not chatbots — AI platforms.
Mental Model Shift
Old thinking:
“We integrate a model into our app.”
New thinking:
“We design an AI system and models are just one component.”
Final Thought
LLMs are not products.
LLMs are not features.
LLMs are not APIs.
LLMs are not chatbots.
They are intelligence engines inside distributed systems.
The future belongs to engineers who understand:
- systems
- architecture
- scalability
- orchestration
- data flows
- reliability
- cost engineering
- AI integration
Not just models.
In the next blog:
We move from understanding LLM systems to understanding how we integrate them into real applications through: