Failures are inevitable in distributed systems.
Servers crash, networks fail, and data centers go down. Good system design focuses not on preventing failures, but on handling them gracefully.
In this blog, we’ll cover fault tolerance, failover, and high availability, and how modern systems stay reliable at scale.
Understanding Failures in Distributed Systems
Common types of failures include:
- Server crashes
- Network timeouts
- Disk failures
- Data center outages
A system must expect failures and continue operating with minimal disruption.
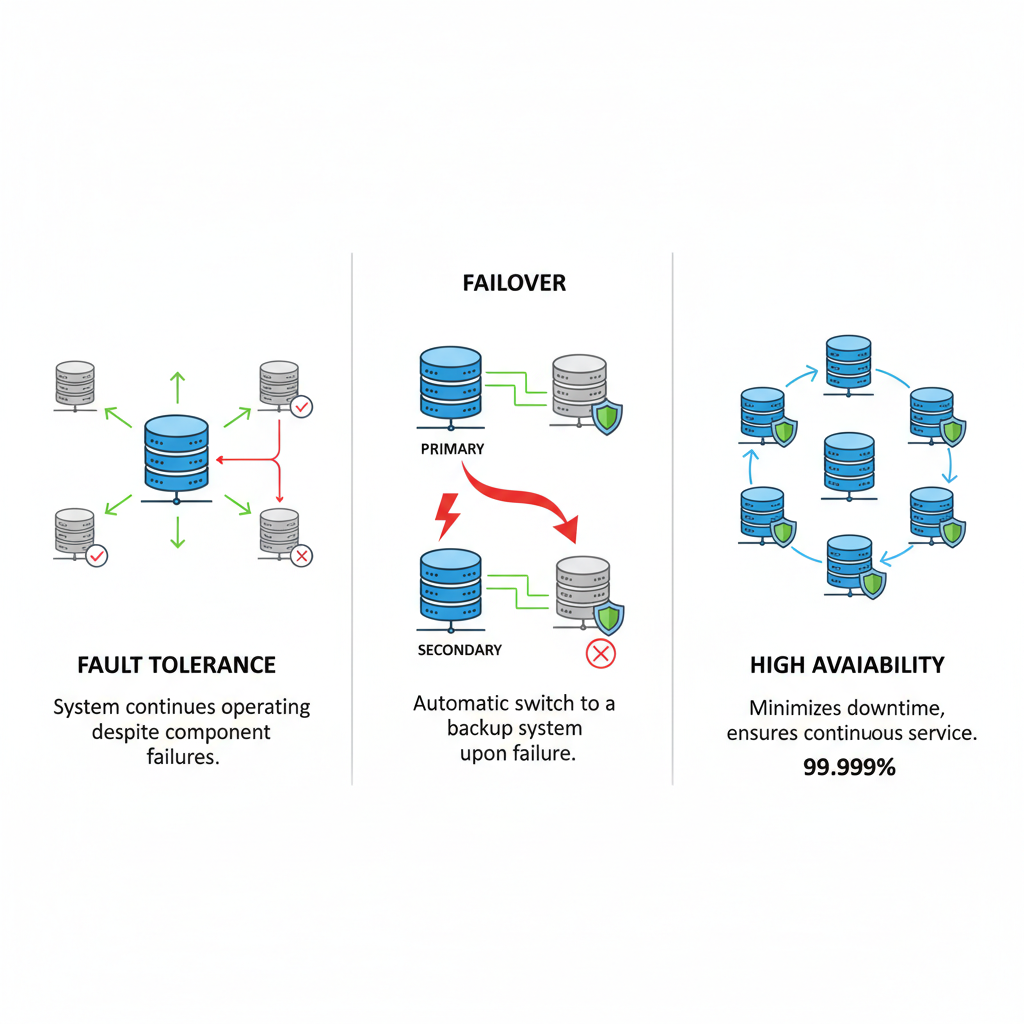
What Is Fault Tolerance?
Fault tolerance is the ability of a system to continue functioning even when components fail.
Key Techniques:
- Redundancy (multiple instances)
- Graceful degradation
- Retries and timeouts
- Idempotent operations
Example:
If one server goes down, traffic is routed to another without user impact.
What Is Failover?
Failover is the process of switching from a failed component to a healthy backup.
Types of Failover:
- Automatic failover: System detects failure and switches instantly
- Manual failover: Human intervention required
Failover reduces downtime but may cause brief service interruptions.
High Availability (HA)
High availability ensures a system is accessible most of the time.
Availability is commonly measured as:
- 99.9% (three nines)
- 99.99% (four nines)
Higher availability requires more redundancy and complexity.
Active–Active vs Active–Passive
Active–Active
- Multiple instances handle traffic simultaneously
- No single point of failure
- More complex data synchronization
Active–Passive
- One active instance handles traffic
- Passive standby takes over on failure
- Simpler but slower failover
Replication & Redundancy
Replication ensures data is copied across:
- Multiple servers
- Multiple availability zones
- Multiple regions
This protects against data loss and regional failures.
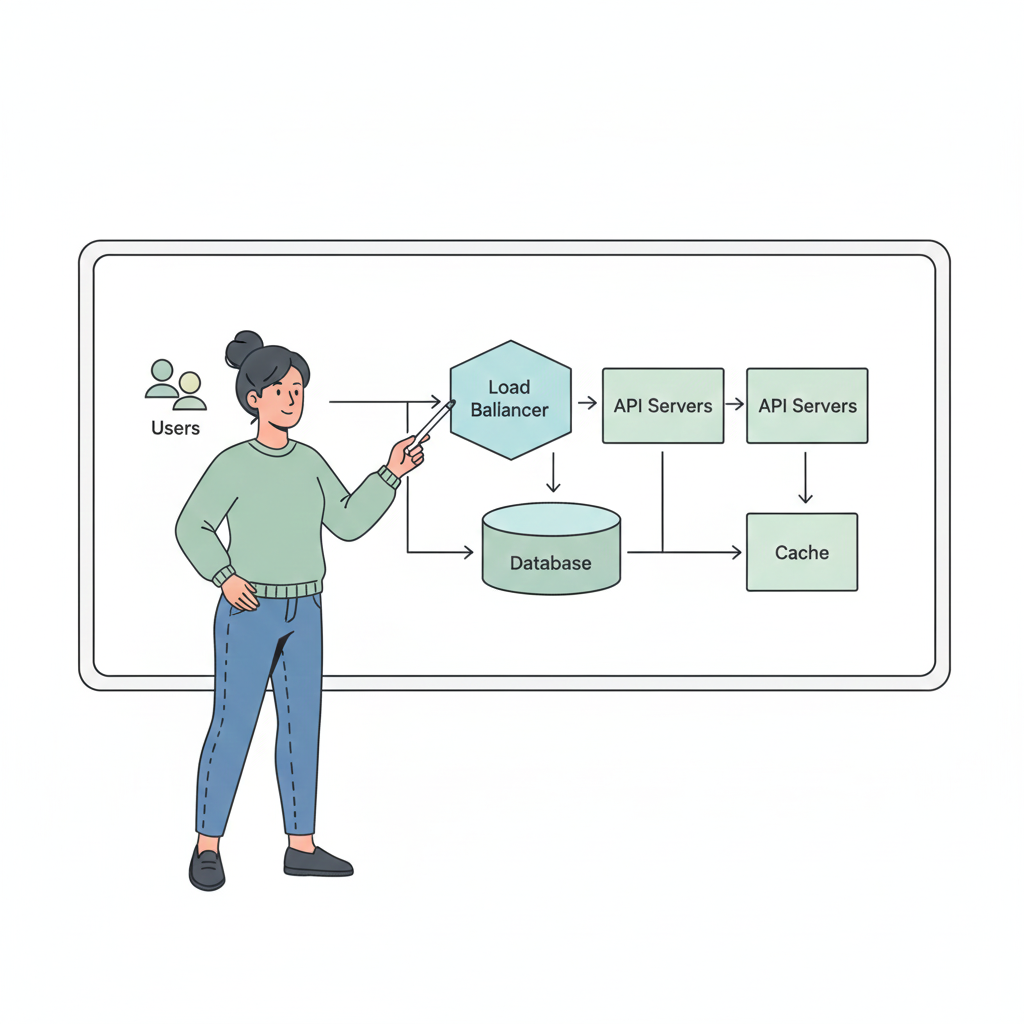
Health Checks & Monitoring
Systems rely on:
- Health checks to detect failures
- Load balancers to route traffic away from unhealthy nodes
- Monitoring and alerting for quick response
Without monitoring, failures go unnoticed.
Handling Partial Failures
Partial failures occur when:
- Some services are slow or unreachable
- System is partially degraded
Best practices:
- Timeouts and retries
- Circuit breakers
- Graceful degradation
Key Takeaways
- Failures are unavoidable
- Fault tolerance keeps systems running
- Failover minimizes downtime
- High availability requires redundancy
- Monitoring and automation are critical
Reliable systems are built by designing for failure.
What’s Next?
In the next blog, we’ll cover:
👉 Distributed Coordination (Locks, Leader Election & Idempotency)
Learn how distributed systems coordinate safely.