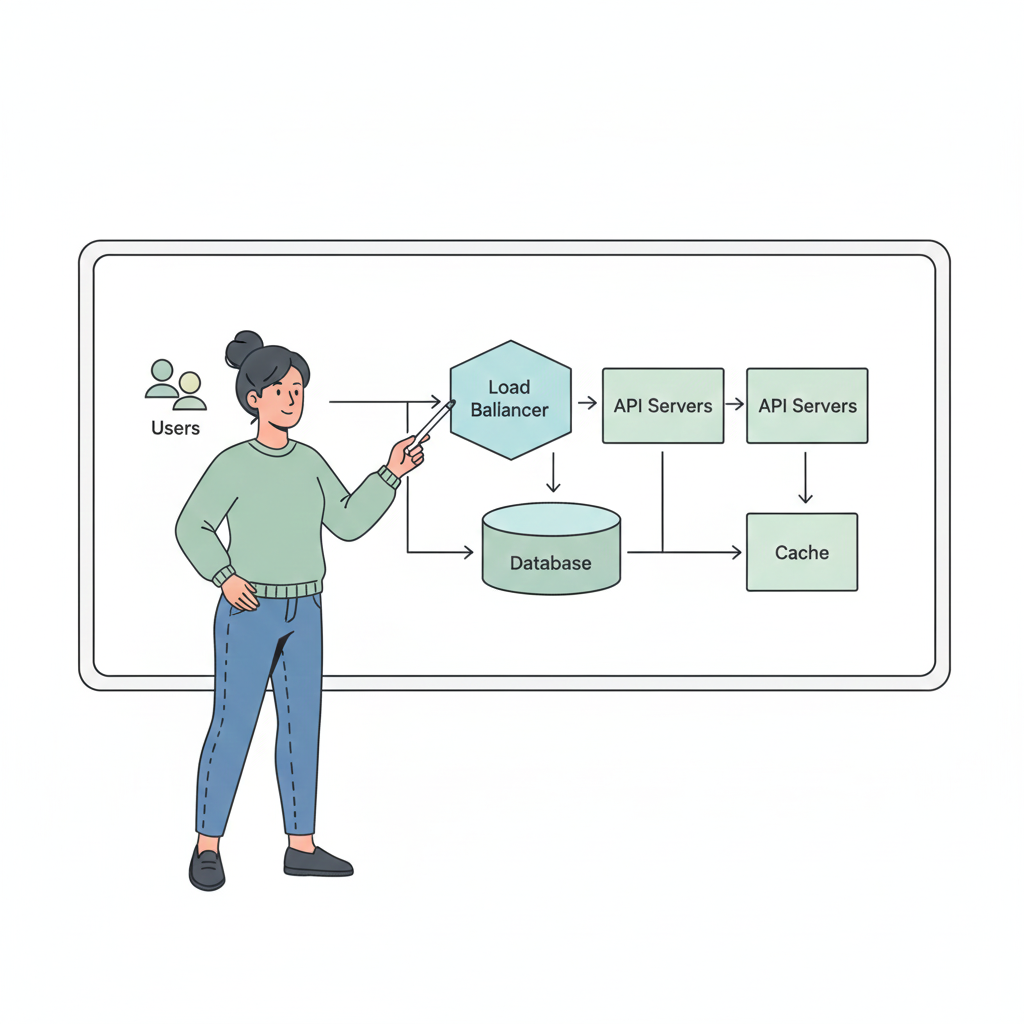
As systems grow, data becomes the hardest part to scale.
Choosing the right database model and scaling strategy directly impacts performance, availability, consistency, and cost.
In this blog, we’ll go deeper into SQL vs NoSQL, sharding, and replication, covering all essential concepts needed for real-world system design and interviews.
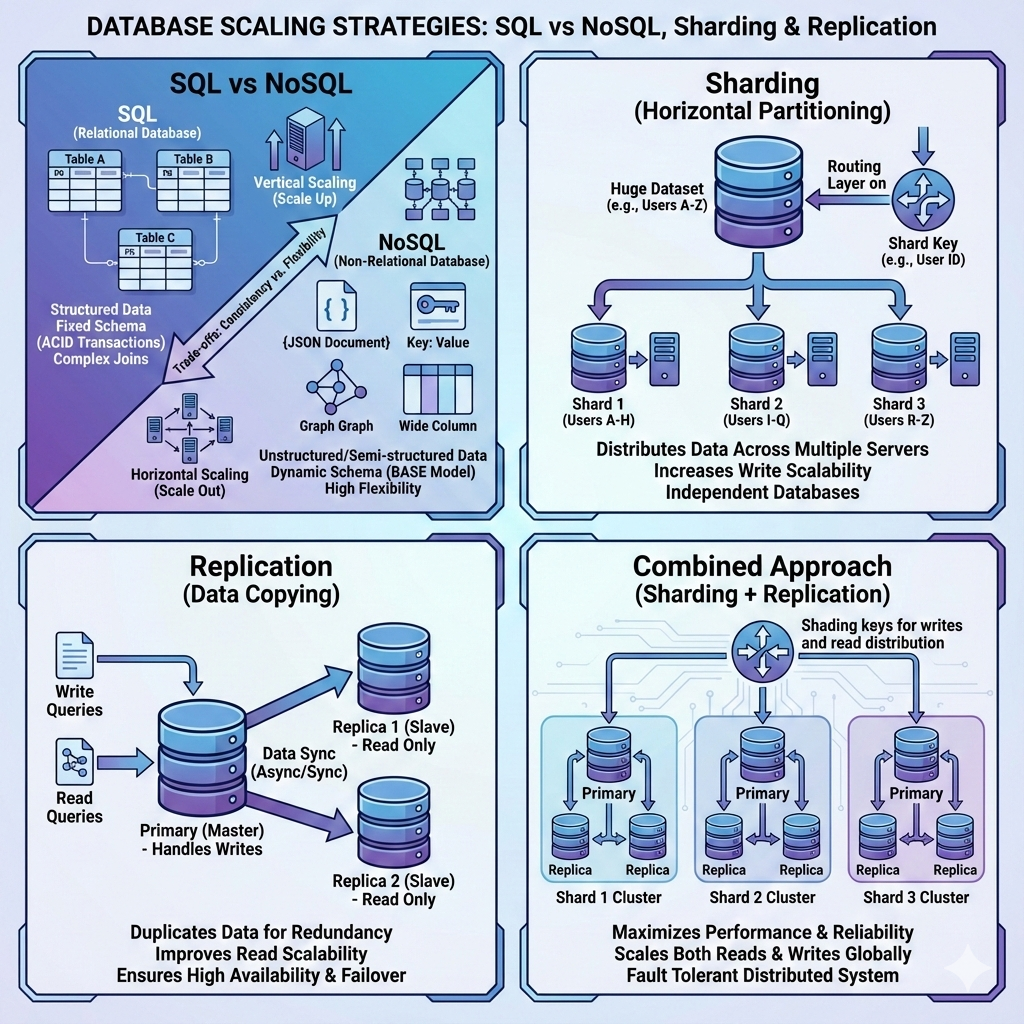
SQL vs NoSQL Databases
SQL Databases (Relational)
SQL databases store data in tables with fixed schemas and support ACID transactions.
Key Characteristics:
- Strong consistency
- Structured data
- Support for joins and complex queries
- Mature tooling and query optimization
When to use SQL:
- Financial systems (payments, banking)
- Order management systems
- Systems with strong relational data
- When correctness is more important than availability
Examples: MySQL, PostgreSQL, Oracle
NoSQL Databases
NoSQL databases are designed for scale, flexibility, and high availability.
Common NoSQL Models:
- Key-Value: Fast lookups (Redis, DynamoDB)
- Document: JSON-like documents (MongoDB)
- Wide-Column: High write throughput (Cassandra)
- Graph: Relationship-heavy data (Neo4j)
Key Characteristics:
- Flexible schemas
- Horizontal scalability
- Often favor availability over consistency
When to use NoSQL:
- Massive scale applications
- Rapidly evolving data models
- Low-latency requirements
- Event logs, metrics, user sessions
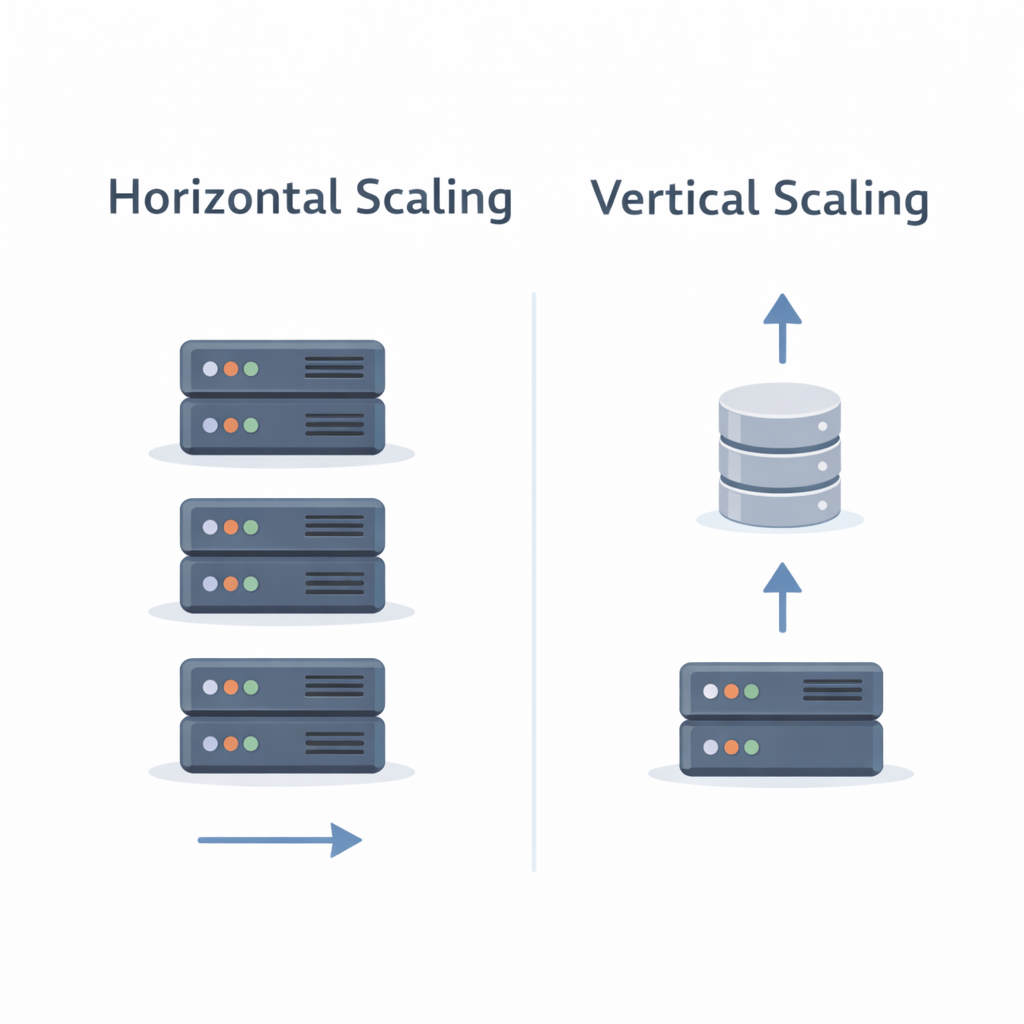
Vertical vs Horizontal Database Scaling
Vertical Scaling
- Increase CPU, RAM, or storage on a single server
- Easy to implement
- Limited by hardware and expensive
Horizontal Scaling
- Distribute data across multiple servers
- Requires data partitioning and replication
- Scales almost infinitely
Most production systems rely on horizontal scaling.
Sharding (Data Partitioning)
Sharding splits data across multiple databases so each shard holds only a portion of the data.
Why Sharding Is Needed
- Single database cannot handle massive data or traffic
- Improves write throughput
- Reduces storage and query load per node
Common Sharding Strategies
1. Range-Based Sharding
Data is split by value ranges.
Example:
User IDs 1–1M → Shard A
User IDs 1M–2M → Shard B
Pros: Simple, readable
Cons: Hot shards if access is uneven
2. Hash-Based Sharding
A hash function determines the shard.
Pros: Even data distribution
Cons: Harder to query ranges
3. Geographic Sharding
Data stored closer to users.
Example:
Asia users → Asia shard
Europe users → Europe shard
Sharding Challenges
- Cross-shard joins are difficult
- Transactions across shards are complex
- Resharding is expensive
Replication
Replication copies data across multiple nodes to improve availability and fault tolerance.
Common Replication Models
Leader–Follower (Primary–Replica)
- Writes go to leader
- Reads served by replicas
Pros: Simple, scalable reads
Cons: Replication lag
Multi-Leader
- Multiple nodes accept writes
Pros: High availability
Cons: Conflict resolution required
Leaderless
- Any node can accept writes
Pros: Fault tolerant
Cons: Eventual consistency
Read Replicas
Read replicas are follower nodes optimized for read traffic.
Use cases:
- Read-heavy applications
- Reporting and analytics
- Search and listing pages
Trade-off:
Data may be slightly stale due to replication lag.
Consistency Considerations
- SQL databases usually provide strong consistency
- NoSQL systems often provide eventual consistency
- Designers must balance consistency, availability, and performance
Key Takeaways
- SQL is best for structured, transactional data
- NoSQL is ideal for scale and flexibility
- Horizontal scaling enables massive growth
- Sharding distributes data; replication improves availability
- Read replicas help scale read-heavy workloads
Database decisions are foundational—changing them later is costly.
What’s Next?
In the next blog, we’ll explore:
👉 Indexing, Search & Read Optimization
Learn how systems speed up reads and handle search at scale.