Scalability is one of the most important concerns in system design.
It defines whether a system can grow smoothly as usage increases or collapses under pressure.
Many engineers understand scalability in theory but struggle to reason about numbers.
This blog focuses on simple, practical scaling concepts and basic estimation techniques that are easy to apply in real systems and interviews.
What Is Scaling?
Scaling is the ability of a system to handle increased load without degrading functionality.
Load can increase in different forms:
- More users
- More requests
- More data
- More traffic
A scalable system adapts to growth with minimal architectural changes.
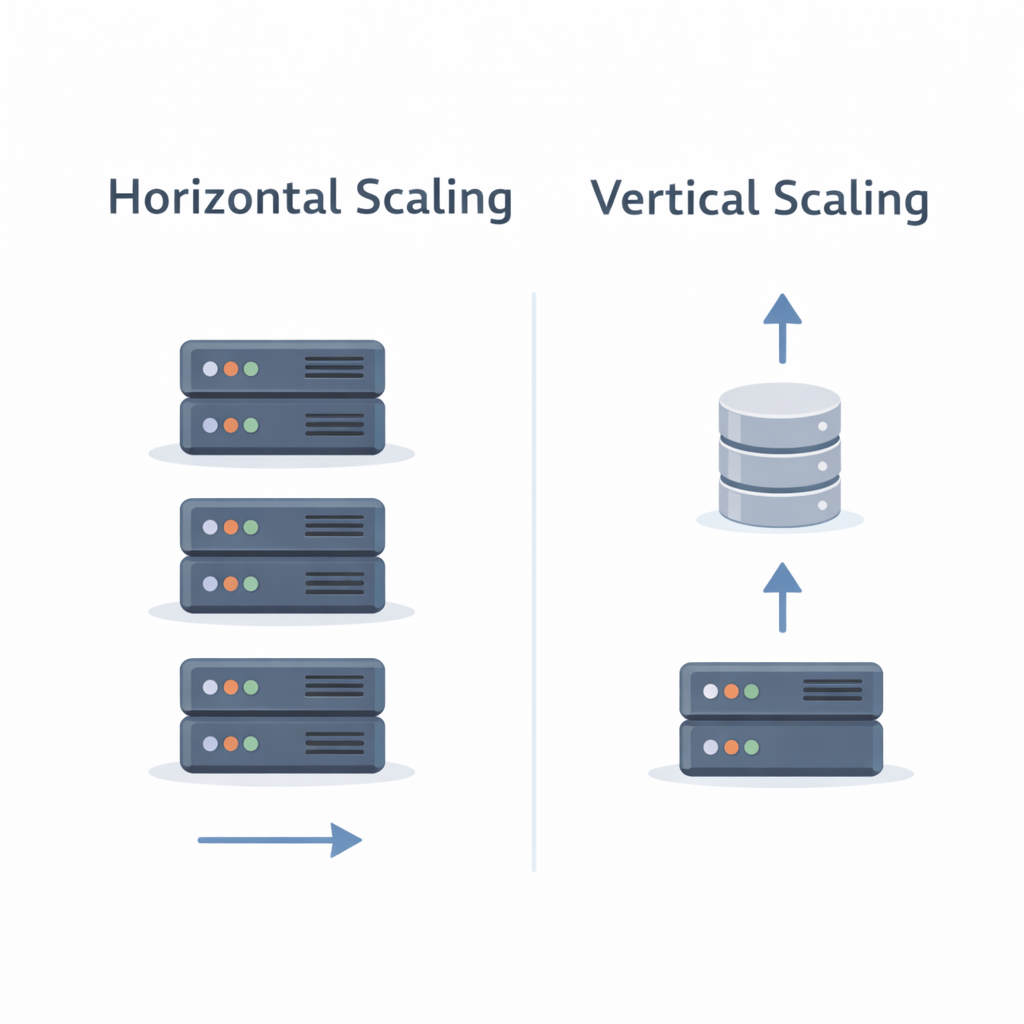
Vertical Scaling (Scale Up)
Vertical scaling means adding more power to a single machine.
Examples:
- More CPU
- More RAM
- Faster disks
Pros
- Simple to implement
- No application-level changes
Cons
- Hardware limits
- Single point of failure
- Expensive at higher scale
Vertical scaling works well for small to medium systems.
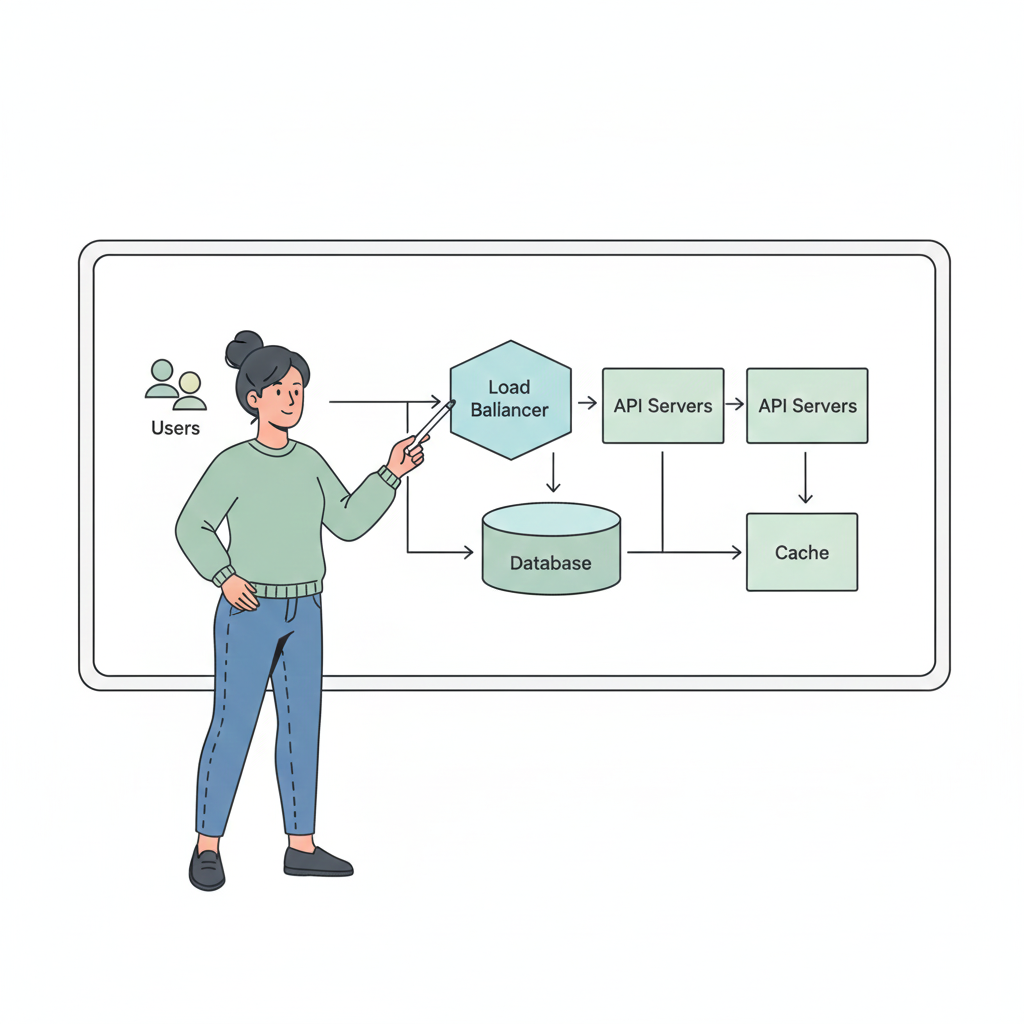
Horizontal Scaling (Scale Out)
Horizontal scaling means adding more machines.
Examples:
- Multiple application servers
- Database replicas
- Distributed caches
Pros
- High scalability
- Better fault tolerance
- Cost-efficient at scale
Cons
- Increased complexity
- Requires stateless design
- Needs load balancing
Most large-scale systems rely on horizontal scaling.
Horizontal vs Vertical Scaling
Vertical scaling increases capacity of one node.
Horizontal scaling increases number of nodes.
As a rule of thumb:
- Start with vertical scaling
- Move to horizontal scaling as growth demands
Why Estimation Matters in System Design
In system design interviews, vague answers are not enough.
Interviewers expect:
- Approximate numbers
- Logical assumptions
- Clear reasoning
Exact accuracy is not required.
Structured thinking is.
Back-of-the-Envelope Estimation
Back-of-the-envelope calculations help you:
- Estimate scale quickly
- Identify bottlenecks
- Justify architectural choices
They are rough calculations meant to guide decisions.
Step 1: Estimate Users
Start with assumptions.
Example:
- 1 million registered users
- 10% daily active users
- 10% concurrent users
That gives:
- 100,000 daily active users
- 10,000 concurrent users
Step 2: Estimate Traffic
Assume:
- Each active user makes 10 requests per day
That results in:
- 1 million requests per day
- ~12 requests per second on average
Always consider peak traffic, not averages.
Step 3: Estimate Storage
Example:
- Each user generates 1 KB of data per day
- 1 million users
That equals:
- 1 GB per day
- ~365 GB per year
Storage grows silently and must be planned early.
Step 4: Estimate Bandwidth
Example:
- Average response size: 5 KB
- 1 million requests per day
That results in:
- ~5 GB outbound traffic per day
Bandwidth matters for cost and performance.
How Estimation Influences Design
Estimation helps answer questions like:
- Do we need caching?
- Do we need sharding?
- Do we need replication?
- Will one database be enough?
Numbers drive architecture, not assumptions.
Common Scaling Mistakes
- Designing for millions of users on day one
- Ignoring peak traffic
- Forgetting storage growth
- Overcomplicating early architecture
Good scaling is incremental, not over-engineered.
Key Takeaways
- Scaling is about handling growth
- Vertical and horizontal scaling solve different problems
- Estimation helps justify design decisions
- Back-of-the-envelope calculations are essential
- Simple assumptions are better than none
What’s Next?
In the next blog, we’ll cover:
👉 CAP Theorem, ACID & BASE
You’ll learn how consistency, availability, and partition tolerance influence system design decisions.